7.8 桶排序
1. 初步认识桶排序
在我们生活的这个世界中到处都是被排序过的。站队的时候会按照身高排序,考试的名次需要按照分数排序,网上购物的时候会按照价格排序,电子邮箱中的邮件按照时间排序……总之很多东西都需要排序,可以说排序是无处不在。现在我们举个具体的例子来介绍一下排序算法。

首先出场的我们的主人公小哼,上面这个可爱的娃就是啦。期末考试完了老师要将同学们的分数按照从高到低排序。小哼的班上只有5个同学,这5个同学分别考了5分、3分、5分、2分和8分,哎考的真是惨不忍睹(满分是10分)。接下来将分数进行从大到小排序,排序后是8 5 5 3 2。你有没有什么好方法编写一段程序,让计算机随机读入5个数然后将这5个数从大到小输出?请先想一想,至少想15分钟再往下看吧(^__^) 。
我们这里只需借助一个一维数组就可以解决这个问题。请确定你真的仔细想过再往下看哦。
首先我们需要申请一个大小为11的数组int a[11]。OK现在你已经有了11个变量,编号从a[0]~a[10]。刚开始的时候,我们将a[0]~a[10]都初始化为0,表示这些分数还都没有人得过。例如a[0]等于0就表示目前还没有人得过0分,同理a[1]等于0就表示目前还没有人得过1分……a[10]等于0就表示目前还没有人得过10分。

下面开始处理每一个人的分数,第一个人的分数是5分,我们就将相对应a[5]的值在原来的基础增加1,即将a[5]的值从0改为1,表示5分出现过了一次。

第二个人的分数是3分,我们就把相对应a[3]的值在原来的基础上增加1,即将a[3]的值从0改为1,表示3分出现过了一次。

注意啦!第三个人的分数也是“5分”,所以a[5]的值需要在此基础上再增加1,即将a[5]的值从1改为2。表示5分出现过了两次。

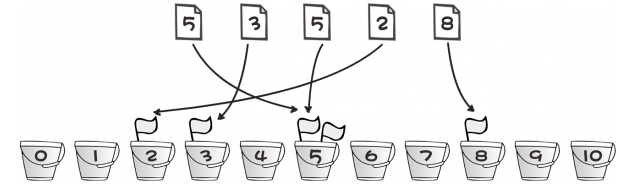
按照刚才的方法处理第四个和第五个人的分数。最终结果就是下面这个图啦。

你发现没有,a[0]~a[10]中的数值其实就是0分到10分每个分数出现的次数。接下来,我们只需要将出现过的分数打印出来就可以了,出现几次就打印几次,具体如下。
a[0]为0,表示“0”没有出现过,不打印。
a[1]为0,表示“1”没有出现过,不打印。
a[2]为1,表示“2”出现过1次,打印2。
a[3]为1,表示“3”出现过1次,打印3。
a[4]为0,表示“4”没有出现过,不打印。
a[5]为2,表示“5”出现过2次,打印5 5。
a[6]为0,表示“6”没有出现过,不打印。
a[7]为0,表示“7”没有出现过,不打印。
a[8]为1,表示“8”出现过1次,打印8。
a[9]为0,表示“9”没有出现过,不打印。
a[10]为0,表示“10”没有出现过,不打印。
最终屏幕输出“2 3 5 5 8”,完整的代码如下。
#include <stdio.h>
int main()
{
int a[11],i,j,t;
for(i=0;i<=10;i++)
a[i]=0; //初始化为0
for(i=1;i<=5;i++) //循环读入5个数
{
scanf("%d",&t); //把每一个数读到变量t中
a[t]++; //进行计数
}
for(i=0;i<=10;i++) //依次判断a[0]~a[10]
for(j=1;j<=a[i];j++) //出现了几次就打印几次
printf("%d ",i);
getchar();getchar();
//这里的getchar();用来暂停程序,以便查看程序输出的内容
//也可以用system("pause");等来代替
return 0;
}
输入数据为
5 3 5 2 8
仔细观察的同学会发现,刚才实现的是从小到大排序。但是我们要求是从大到小排序,这该怎么办呢?还是先自己想一想再往下看哦。
其实很简单。只需要将for(i=0;i<=10;i++)改为for(i=10;i>=0;i--)就OK啦,快去试一试吧。
这种排序方法我们暂且叫他“桶排序”。因为其实真正的桶排序要比这个复杂一些,以后再详细讨论,目前此算法已经能够满足我们的需求了。
这个算法就好比有11个桶,编号从0~10。每出现一个数,就将对应编号的桶中的放一个小旗子,最后只要数数每个桶中有几个小旗子就OK了。例如2号桶中有1个小旗子,表示2出现了一次;3号桶中有1个小旗子,表示3出现了一次;5号桶中有2个小旗子,表示5出现了两次;8号桶中有1个小旗子,表示8出现了一次。
现在你可以请尝试一下输入n个0~1000之间的整数,将他们从大到小排序。提醒一下如果需要对数据范围在0~1000之间的整数进行排序,我们需要1001个桶,来表示0~1000之间每一个数出现的次数,这一点一定要注意。另外此处的每一个桶的作用其实就是“标记”每个数出现的次数,因此我喜欢将之前的数组a换个更贴切的名字book(book这个单词有记录、标记的意思),代码实现如下。
#include <stdio.h>
int main()
{
int book[1001],i,j,t,n;
for(i=0;i<=1000;i++)
book[i]=0;
scanf("%d",&n);//输入一个数n,表示接下来有n个数
for(i=1;i<=n;i++)//循环读入n个数,并进行桶排序
{
scanf("%d",&t); //把每一个数读到变量t中
book[t]++; //进行计数,对编号为t的桶放一个小旗子
}
for(i=1000;i>=0;i--) //依次判断编号1000~0的桶
for(j=1;j<=book[i];j++) //出现了几次就将桶的编号打印几次
printf("%d ",i);
getchar();getchar();
return 0;
}
可以输入以下数据进行验证
10
8 100 50 22 15 6 1 1000 999 0
运行结果是
1000 999 100 50 22 15 8 6 1 0
最后来说下时间复杂度的问题。代码中第6行的循环一共循环了m次(m为桶的个数),第9行的代码循环了n次(n为待排序数的个数),第14和15行一共循环了m+n次。所以整个排序算法一共执行了m+n+m+n次。我们用大写字母O来表示时间复杂度,因此该算法的时间复杂度是O(m+n+m+n)即O(2*(m+n))。我们在说时间复杂度时候可以忽略较小的常数,最终桶排序的时间复杂度为O(m+n)。还有一点,在表示时间复杂度的时候,n和m通常用大写字母即O(M+N)。
这是一个非常快的排序算法。桶排序从1956年就开始被使用,该算法的基本思想是由E.J.Issac和R.C.Singleton提出来。之前我有说过,其实这并不是真正的桶排序算法,真正的桶排序算法要比这个更加复杂。接下来我们来学习真正的桶排序。
2. 桶排序
桶排序(Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶里。每个桶再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序),最后依次把各个桶中的记录列出来记得到有序序列。桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是比较排序,他不受到O(n log n)下限的影响。
2.1 基本思想
桶排序的思想近乎彻底的分治思想。 桶排序假设待排序的一组数均匀独立的分布在一个范围中,并将这一范围划分成几个子范围(桶)。
然后基于某种映射函数f ,将待排序列的关键字 k 映射到第i个桶中 (即桶数组B 的下标i) ,那么该关键字k 就作为 B[i]中的元素 (每个桶B[i]都是一组大小为N/M 的序列 )。
接着将各个桶中的数据有序的合并起来 : 对每个桶B[i] 中的所有元素进行比较排序 (可以使用快排)。然后依次枚举输出 B[0]….B[M] 中的全部内容即是一个有序序列。
补充: 映射函数一般是 f = array[i] / k; k^2 = n; n是所有元素个数
为了使桶排序更加高效,我们需要做到这两点:
在额外空间充足的情况下,尽量增大桶的数量
使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
2.2 实现逻辑
设置一个定量的数组当作空桶子。 寻访序列,并且把项目一个一个放到对应的桶子去。 对每个不是空的桶子进行排序。 从不是空的桶子里把项目再放回原来的序列中。
2.3 动图演示
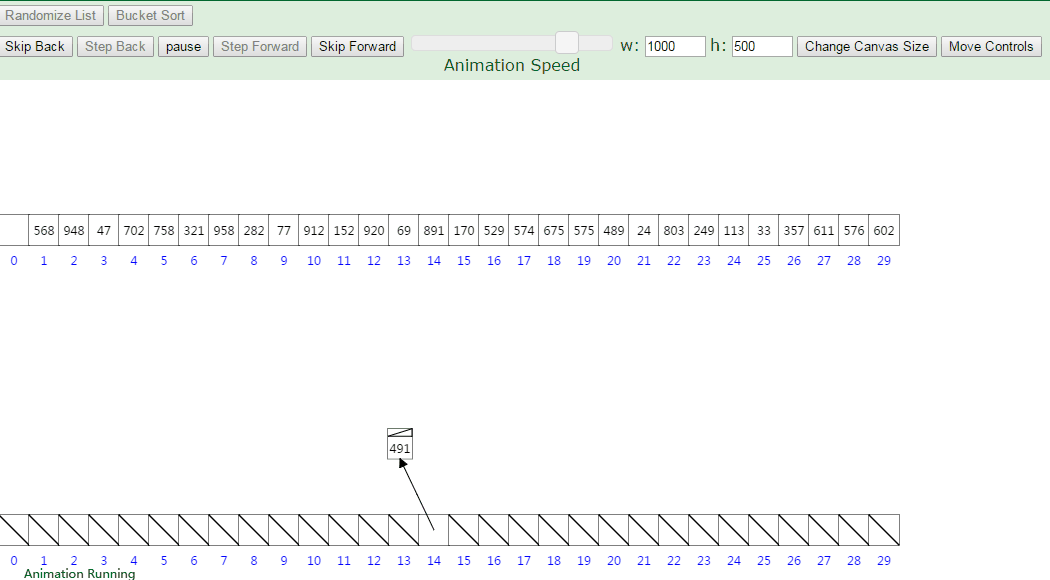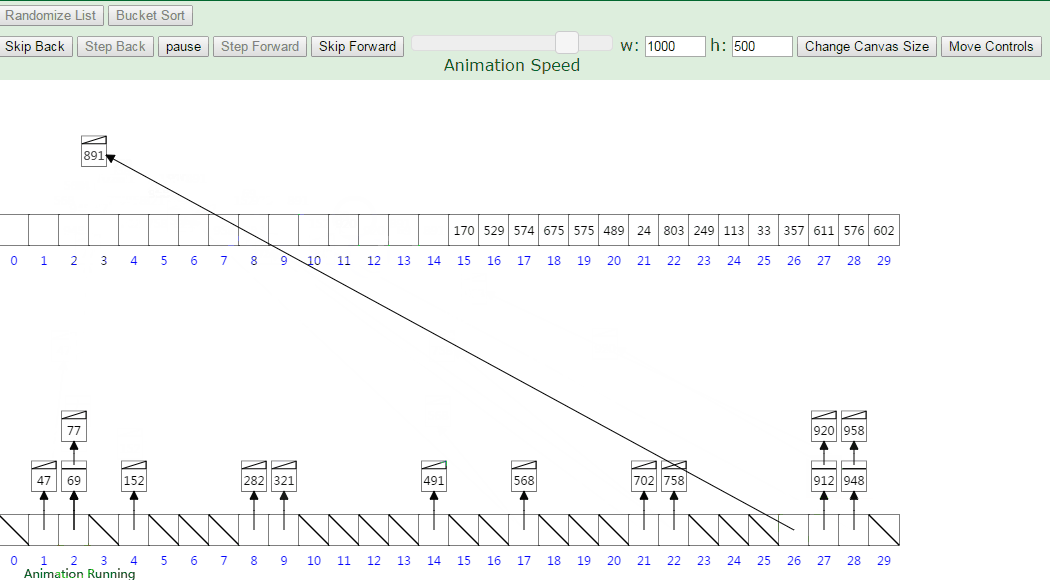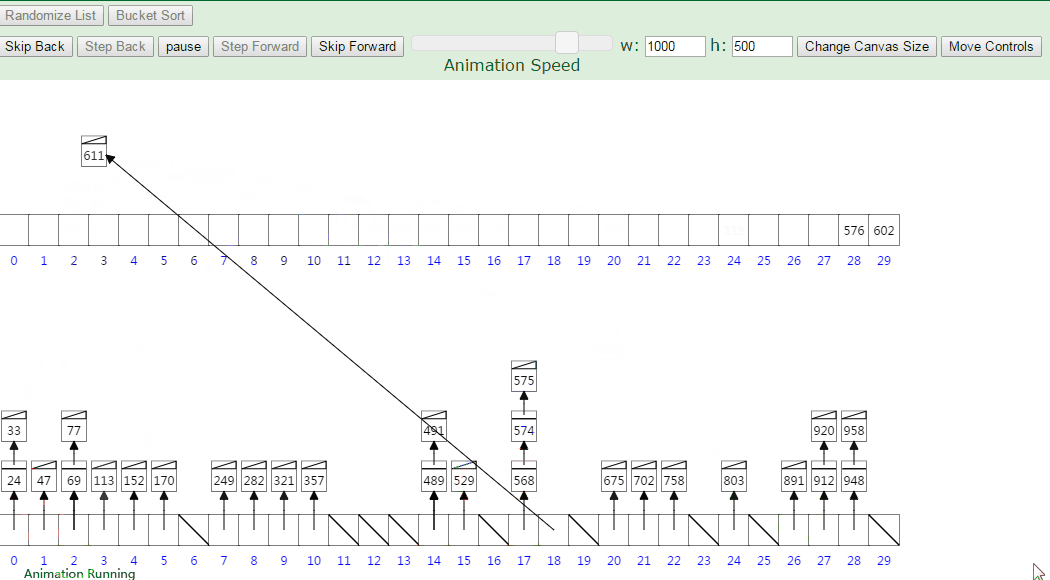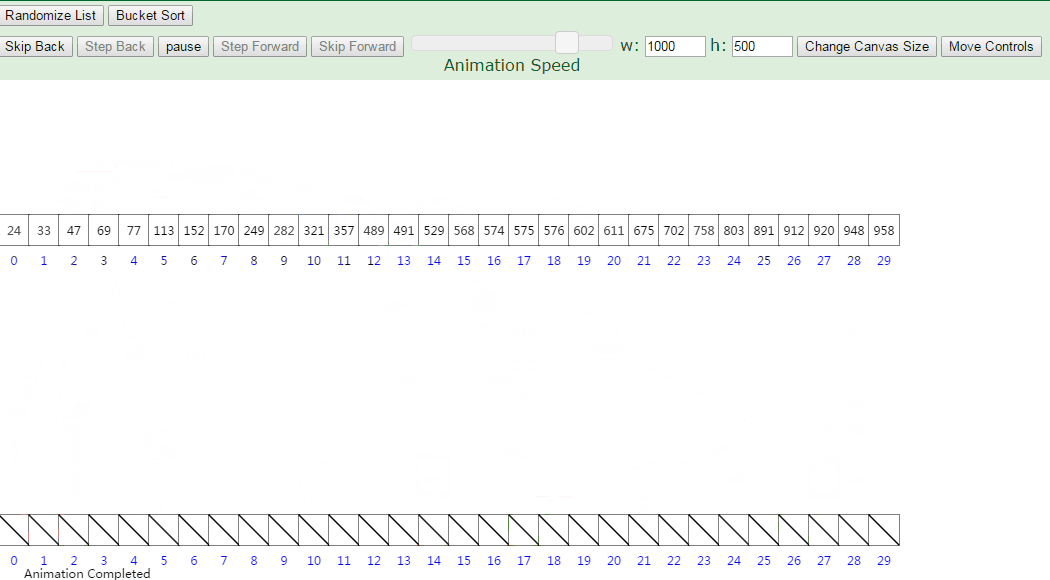
分步骤图示说明:设有数组 array = [63, 157, 189, 51, 101, 47, 141, 121, 157, 156, 194, 117, 98, 139, 67, 133, 181, 13, 28, 109],对其进行桶排序:

2.4 复杂度分析
平均时间复杂度:O(n + k)
最佳时间复杂度:O(n + k)
最差时间复杂度:O(n ^ 2)
空间复杂度:O(n * k)
稳定性:稳定
桶排序最好情况下使用线性时间O(n),桶排序的时间复杂度,取决与对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为O(n)。很显然,桶划分的越小,各个桶之间的数据越少,排序所用的时间也会越少。但相应的空间消耗就会增大。
2.5 代码实现(C实现)
假设数据分布在[0,100)之间,每个桶内部用链表表示,在数据入桶的同时插入排序。然后把各个桶中的数据合并。
#include<iterator>
#include<iostream>
#include<vector>
using namespace std;
const int BUCKET_NUM = 10;
struct ListNode{
explicit ListNode(int i=0):mData(i),mNext(NULL){}
ListNode* mNext;
int mData;
};
ListNode* insert(ListNode* head,int val){
ListNode dummyNode;
ListNode *newNode = new ListNode(val);
ListNode *pre,*curr;
dummyNode.mNext = head;
pre = &dummyNode;
curr = head;
while(NULL!=curr && curr->mData<=val){
pre = curr;
curr = curr->mNext;
}
newNode->mNext = curr;
pre->mNext = newNode;
return dummyNode.mNext;
}
ListNode* Merge(ListNode *head1,ListNode *head2){
ListNode dummyNode;
ListNode *dummy = &dummyNode;
while(NULL!=head1 && NULL!=head2){
if(head1->mData <= head2->mData){
dummy->mNext = head1;
head1 = head1->mNext;
}else{
dummy->mNext = head2;
head2 = head2->mNext;
}
dummy = dummy->mNext;
}
if(NULL!=head1) dummy->mNext = head1;
if(NULL!=head2) dummy->mNext = head2;
return dummyNode.mNext;
}
void BucketSort(int n,int arr[]){
vector<ListNode*> buckets(BUCKET_NUM,(ListNode*)(0));
for(int i=0;i<n;++i){
int index = arr[i]/BUCKET_NUM;
ListNode *head = buckets.at(index);
buckets.at(index) = insert(head,arr[i]);
}
ListNode *head = buckets.at(0);
for(int i=1;i<BUCKET_NUM;++i){
head = Merge(head,buckets.at(i));
}
for(int i=0;i<n;++i){
arr[i] = head->mData;
head = head->mNext;
}
}
2.6 总结
桶排序是计数排序的变种,它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。把计数排序中相邻的m个”小桶”放到一个”大桶”中,在分完桶后,对每个桶进行排序(一般用快排),然后合并成最后的结果。
算法思想和散列中的开散列法差不多,当冲突时放入同一个桶中;可应用于数据量分布比较均匀,或比较侧重于区间数量时。
桶排序最关键的建桶,如果桶设计得不好的话桶排序是几乎没有作用的。通常情况下,上下界有两种取法,第一种是取一个10^n或者是2^n的数,方便实现。另一种是取数列的最大值和最小值然后均分作桶.